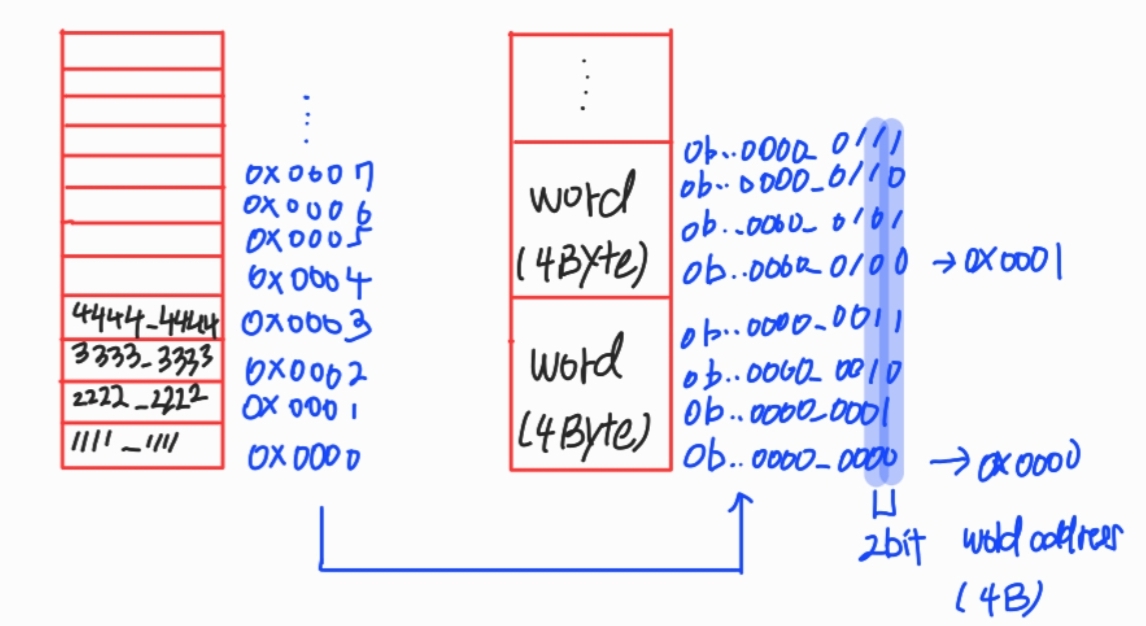
address의 개념을 잡고 가자.
메인 메모리는 byte로 구성돼 있다. Word는 4byte로 구성돼 있는데. Word address는 byte 주소를 2진수로 바꿨을 때, 제일 오른쪽 2개 비트를 제외하고 제일 첫 번째 주소를 Word주소로 취한다.
이게 왜 이렇게 되냐면, 4byte는 4번마다 00, 01, 10, 11이 반복되는데 이 반복되는 건 의미가 없기 때문에 무시하고 주소를 얻는 것이다.
그렇다면 Block address는 어떻게 구할까?? 아래를 보면 block address는 cache size에 따라 달라진다. cache size는 쉽게 말해 캐시의 저장 공간 크기다. 16byte라면 하나의 entry에 16byte를 저장할 수 있다는 의미다. 32byte라면 아래 5 bit를 무시하고 address를 적용한다. 이 주소가 cache의 TAG에 들어가는 것이다.

Cache에는 3가지 종류가 있는데 그중에 하나인 Direct-Mapped-Cache를 보자
Direct-Mapped-Cache
캐시와 메인 메모리 사이에서 데이터를 저장할 때, 캐시의 사이즈가 작기 때문에 메인 메모리는 논리적으로 나눠서 짝을 맞춰 저장한다. 아래와 같이 말이다. 메인 메모리에서 물리적으로 나눠져 있진 않지만, 논리적으로 나눠져 있다. cache size에 맞춰서 말이다. 즉, 캐시를 공유하는데 짝을 지어 공유하는 걸 Direct-Mapped-Cache라고 한다.

위 그림을 보면 block size는 4 byte고, entry는 8개가 있다 이에 32byte 캐시다.
4byte라 2bit는 무시한다. 즉 block address가 0000_00에서 시작한다. 그런데 보면 빨간색과 보라색이 같은 entry를 가리키고 있다. 이유는 뭘까? DM$는 캐시 사이즈에 맞게 메인 메모리를 논리적으로 나눠져 있기 때문에 겹치는 캐시의 위치가 존재하기 마련이다. 예를 들어 캐시 사이즈가 4이고 메인 메모리가 16이라면 메인 메모리의 0번째와 4번째 8번째 12번째가 같은 위치를 공유할 것이다.
이와 똑같다. 무시하는 비트를 제외하고 enrty가 8개니, 3bit는 어떤 entry에 저장될지 결정하고 TAG에는 chunk id라는 주소를 넣는다. (공식적인 이름은 아니다)
chunk는 덩어리라는 의미로 entry를 제외하고 나머지 bit를 의미한다. 위에선 동그라미 친 애들이 chunk id이다. 이해하는데 시간이 필요하다. 종이를 꺼내 한번 적어보면 이해가 될 것이다.
동작의 예를 들어보자, 다음과 같은 명령어를 수행한다고 하자
lw x1, 24(zero)
sw x3, 60(zero)
sw x4, 188(zero)

위와 같은 cache에서 컴퓨터를 처음 켰을 때 valid와 Dirty는 모두 0으로 돼 있다. cpu는 8bit wide라고 가정하자.
# lw x1, 24(zero)
24는 8bit로 표현하면, 0001_1000이다. block size가 4byte이므로 제일 오른쪽 2bit는 무시하고 어떤 entry를 정하느냐는 다음 3bit를 기준으로 정한다. 여기선 110이니 entry 6을 선택한다. 또한 TAG에는 chunk id인 000이 들어간다.
그리고 valid는 1로 바뀐다. (miss)
index = 6
valid = 1
Tag = 000
Data = 메인 메모리에 있는 데이터
Dirty = 0
# sw x3 60(zero)
60을 8bit로 바꾸면 0011_1100이다. index, valid, Tag는 똑같이 적용되지만, sw는 레지스터에 있는 메모리는 메인 메모리로 옮기는 작업이다. 그렇다면 메인 메모리에 있는 데이터(address 60)를 가져올 필요가 있을까?
일단 가져와서 캐시에 저장한다. 이 작업을 Write-allocation policy라고 한다.
그리고 x3로부터 데이터를 가져와서 데이터를 덮는다. 여기서 끝날까? sw의 궁극적인 목적은 메인 메모리에 데이터를 저장하는 것이다. 하지만, 당장을 캐시에만 저장한다. 메인 메모리에는 나중에 저장한다. 이유는 메인 메모리가 너무 느리기 때문이다. 이걸 Write-back (or Write-through) policy라고 한다.
그럼 언제 업데이트할까? 이때 필요한 게 Dirty bit가 필요하다. 즉, 나중에 update를 해야 한다면 1로 세팅된다. (miss, chunk id가 같아야 hit)
index = 7
valid = 1
Tag = 001
Data = x3 데이터
Dirty = 1
# sw x4 188(zreo)
188은 8bit로 바꾸면 1011_1100이다. 그런데 이미 entry 7에 x3의 데이터가 들어있고, 아직 메인 메모리에 update까지 하지 않은 상태다. 이런 상태에서 같은 entry로 miss가 일어나면, Dirty bit가 1로 set 되어 있으니, 메인 메모리에 update를 먼저 한다.
그리고 다시 address 188에 있는 데이터를 가져오고 (Write-allocation policy), x4 데이터를 덮어서 저장한다 (Write-back). 즉 위에서 일어났던 동작이 반복된다
index = 7
valid = 1
Tag = 101
Data = x4 데이터
Dirty = 1
Write
write에는 4가지 동작이 있다
1. Write-allocation policy : 메인 메모리의 데이터를 일단 가져오는 것, hit가 일어나면 동작하지 않음
2. Write-no-allocation policy : 메인 메모리의 데이터를 가져오지 않는 것, hit가 일어나면 동작하지 않음
3. Write-back policy : CPU로부터 캐시에 데이터를 저장하고 메인 메모리에는 저장하지 않는 것
4. Write-through policy : CPU로부터 캐시에 데이터를 저장하고 메인 메모리에는 저장까지 하는 것
보통 allocation과 back이 짝을 짓고 no-allocation와 through 이 짝을 지어 동작한다




댓글