cpu와 memory사이에서 데이터를 주고받는데 이때 cpu는 memory한테 주소를 전달하고 반환될 때까지 기다린다.
다시 말해 cpu 내부에서의 처리는 빠르지만 메모리로부터 불러오는데 시간이 오래 걸린다는 말이다.
조금 바꿔 말하면 pipeline에서 Fetch는 오래 걸리고 Decoding, Execution은 빨리 처리한다는 의미다.
예를 들어 5 stage pipeline design인데 cpu는 1 GHz(1ns)라고 하자, memory로부터 정보를 얻는 시간은 100ns이다.

이런 식이니 메모리로부터 Fetch 하는데 너무 많은 시간이 든다. 꼭 메인 메모리로부터 가져와야 할까? 하는 생각을 하다 해결방안으로 나온 것이 Cache이다.
Cache
캐시는 프로세서 안에 cpu와 메인 메모리 사이에 있는 매우 작아지고 (메인 메모리보다 약 1000배 작음) 매우 빠른 장치다. 즉 임시 저장소와 같은 역할이다.
컴퓨터를 처음 켰을 때 cache는 비어있다가. cpu가 메인 메모리로부터 request 하면 메인 메모리는 정보를 cpu한테 전해줘야 하는데 이때 그 정보를 cache가 저장한다. 그리고 다음에 cpu가 같은 정보를 요청하면 이때 cache에 있던 정보를 바로 전해줌으로 시간을 줄일 수 있다.
core 2 Duo라고 가정하면 cache는 L2, DL1, IL1이 있다.

L2는 2개의 core가 공통적으로 사용하는 캐시며 Data, Instruction 둘 다 저장 가능하다.
DL1는 각각의 core에 존재하는데 Data만 저장할 수 있다.
IL1도 각각의 core에 존재하며 Instruction만 저장될 수 있다.
근데 캐시는 굉장히 작은데 상대적으로 매우 큰 메인 메모리로부터 어떻게 가져와 저장할 수 있을까?
이건 Locality (지역성) 때문이다. 지역성에는 2가지 종류가 있다.
Locality
1. Temporal Locality (locality in time)
- cpu가 lw x5, 4(x0) 명령어를 동작한다 했을 때, 메인 메모리에서 목적지 x0를 얻는다. 근데 x0가 가까운 미래에 또 사용될 확률이 매우 높으니 이 데이터를 캐시에 저장한다. 이걸 시간 지역성이라고 한다.
2. Spatial Locality (locality in space)
- 한번 접근한 데이터로부터 주변의 데이터를 또 사용할 것이라고 생각해 그 주변을 데이터까지 캐시로 가져오는 것이다. 대표적으로 배열이 이에 해당된다.
예를 들어보자
int a[100], b[100], d;
for (int i=0; i<100 ; i++) {
b[i] = a[i] + d;
}
위와 같은 경우에서 Temporal locality는 같은 데이터인 d를 100번 반복해야 하며 또한 i도 계속 비교를 해야 하니 마찬가지다. 처음에는 메인 메모리에서 가져오지만 다음부터는 캐시에서 가져올 수 있다.
Spatial locality는 a [100], b [100]이다. 처음 동작할 때, a [0], b [0]를 가져오면서 나머지 모든 데이터를 cache로 가져온다. 이런 이유로 선언이 굉장히 중요하다.
그렇다면 궁금한 게 생긴다. cpu와 캐시, 캐시와 메인 메모리 사이의 데이터의 교환은 누가 관리할까??
메인 메모리 - 디스크 : 프로그래머와 운영체제가 관리한다.
CPU - 메인 메모리 : 프로그래머와 컴파일러가 관리한다.
Cache - 메인 메모리 : cache controller가 관리한다.
cache 동작
캐시의 동작을 예로 보자. 아래 그림에서 다음과 같은 동작을 한다고 가정하자. (Direct-Mapped-Cache)
lw x1, 0x4(zero)
lw x2, 0xC(zero)
lw x3, 0x1208(zero)
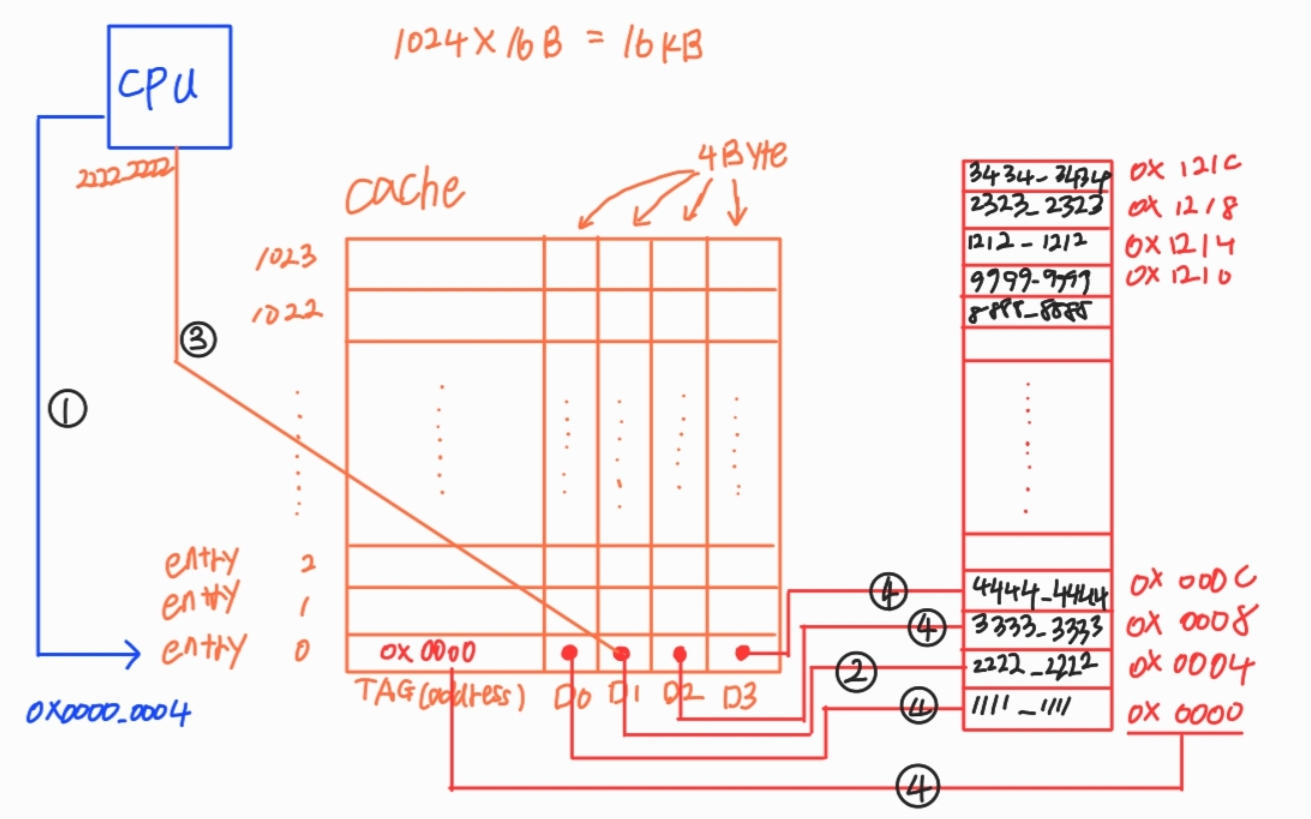
위의 예시에서 캐시의 크기는 1024(1K) x 16byte = 16MB의 크기다. 4byte는 32bit이니 16진수로 xxxx_xxxx를 담을 수 있다.
0~1023을 entry라고 하고, D1, D2와 같은 애들은 하나의 데이터를 담을 수 있고 4Byte의 크기를 담을 수 있다.
그 옆에 TAG는 메인 메모리의 주소를 저장한다.
# lw x1, 0x4(zero)
동작을 보면 처음에 cpu가 전달해준 주소를 하나의 entry가 가지고만 있는다. 이걸 캐시 miss라고 부른다.
다음으로 해당 주소에 있는 데이터를 cache에 저장하고 CPU로 전달한다.
그다음엔 그 주변에 있는 데이터를 block단위로 저장하고 TAG에는 block address를 저장한다.
(+ 메인 메모리에서는 cache line size에 맞게 논리적으로 block으로 나누고 이걸 memory block이라고 부른다.)
# lw x2, 0xC(zero)
이 동작을 수행하니 이미 cache에 데이터가 존재한다. 그러니 메인 메모리까지 가지 않고, cache에서 전달한다. 이런 동작을 cache hit라고 한다.
# lw x3, 0x1208(zero)
이 동작을 수행하면 cpu는 0x1208을 enrty 1022를 선택하여 cache miss 한다. 왜 entry 1을 선택하지 않고 1022를 할까?? 그건 위에서 말한 것과 같이 cache size에 맞게 메인 메모리가 논리적으로 구분돼 있기 때문이다. 조금 다르게 말하면 짝이 정해져 있는 것이다. 나머진 위와 똑같이 동작한다.
정리하면, cache는 하나의 데이터만 저장하는 게 아니라 cache line size의 block 단위로 메인 메모리와 데이터를 주고받는다. 이렇게 저장하니 두 locality가 모두 가능한 것이다. 위 동작은 사실 정확한 동작이 아니다. 더 디테일 한 부분은 다음 포스팅에 올리겠다.




댓글