먼저 비교를 통해 어떤 구조가 더 좋은지 보자.
하나는 2개의 프로세서가 2개의 core가 각각 존재하고, 다른 하나는 1개의 프로세서에 2개의 core가 있다고 가정해보자,
어떤 구조가 더 좋을까?
후자가 더 좋다. 이유는 뭘까?? 이렇게 생각해보자, Dual Processor에서 하나의 core에서 프로세스가 돌아가다가 중간에 나왔다가 다시 구동될 때 다른 core로 들어가면 어떻게 될까?? 이때는 메모리로부터 새로 불러와야 된다.
하지만 하나의 프로세서에 2개의 core 중에 하나에서 구동하다가 다시 실행한다고 했을 때, 다른 core에 들어가도 서로 공유 cache를 사용하고 있기 때문에 메모리로부터 새로 불러 들어오지 않아도 된다. 훨씬 빠르다는 의미다.
이렇게 동작하는 프로세서를 CMT 혹은 SMT 혹은 Hyper-threading이라고 부른다.

만약 quad core system에 2개의 threads가 있다고 보자, 그러면 운영체제는 8개의 core가 있다고 생각한다. 그림을 보자.
아래와 같은 system을 4 way SMT라고 부른다.
이렇게 구조가 바꿔왔다. 요즘은 NUMA ( Non-Uniform Memory Access ) system의 구조를 사용한다.
NUMA ( Non-Uniform Memory Access )
아래처럼 여러 개의 코어가 있고 각각의 코어의 바로 옆에 메모리를 붙여놨다. 만약 어떤 프로세스를 실행할 때, 어느 메모리에 할당하지 했을 때, NUMA에서는 모든 core의 메모리에 할당 가능하다.
이렇게 다른 core의 메모리에도 접근 가능하기 때문에 Non-Uniform Memory Access, 즉 메모리의 접근이 균일하지 않다는 의미를 가진 구조다.
하지만 당연히 자기 메모리에 접근하는 게 가장 빠른데 만약 다른 메모리에 할당된다면 load 하는데 더 많은 시간이 든다.
예를 들어 8개의 core가 있을 때 각각의 core 메모리에 접근하는 시간을 나타낸다. 자신의 메모리에 접근할 때는 동일하게 10이라는 시간이 걸리지만 멀리 있을수록 더 많은 시간이 들어가는 걸 볼 수 있다.
운영체제는 이런 구조에서 어느 core에 프로세스를 할당하고 메모리를 잡아야 할지 scheduling을 해야 한다. 이렇듯 localization 즉, 지역성을 고려하여 scheduling을 해야 한다. 이렇게 고려한 NUMA를 Automatic NUMA Balancing이라 한다.
Automatic NUMA Balancing
- Multiple-Processor Scheduling과 똑같이 balancing을 할 때 reschedule은 이전에 수행했던 core로 다시 재배정을 받는 방식( Task migration )과 메모리를 page 단위로 복사하여 자신의 core 메모리로 옮기는 방식이 있다 ( page migration ).
구현으로는 Task grouping과 Pseudo interleaving이 있다.
Task grouping이란 같은 task을 모아주는 것이다. 가령 2개의 task가 서로 다른 core에서 돌아간다고 하면 2개의 core ㅔ메모리에 접근해야 한다. 이렇게 같은 task라면 하나의 core로 group을 만들어서 메모리 접근을 통일하는 방식이다.
Pseudo interleaving이란 task에 필요한 메모리가 하나의 core 메모리에 몰리는 현상을 방지하고자 메모리 할당에 분산을 시킨 것이다.
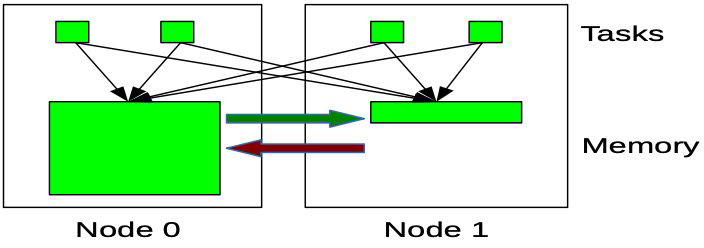
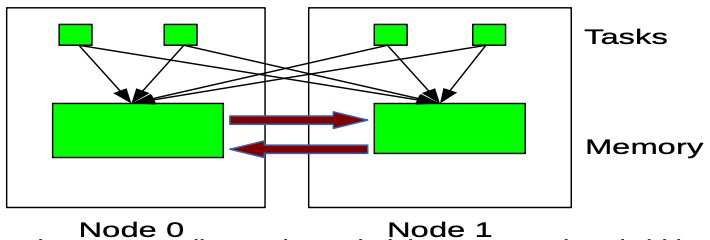
이렇게 메모리의 접근에서 더 좋은 효율을 낸다.




댓글