O(N) Algorithm
- version 2.4에는 O(N) algorithm을 사용했다. 단순히 N개의 프로세스가 있는 ready queue를 확인하며 우선순위에 따라 time quantum 기준으로 실행했다. 이러니 프로세스가 많으면 많은 시간이 걸린다는 단점이 있다.
Q(1) Algorithm
- version 2.6에서는 O(1) algorithm을 사용했다. O(1)은 runqueue를 이용하여 프로세스의 수와 상관없이 queue마다 정해진 시간(constant time) 동안 task를 동작하는 것이다.
# run queue란, cpu에 실행되기 전에 대기하는 queue라고 생각하면 되는데 Active(활성) array와 Expired(만료) array로 나눈다.
O(1) 알고리즘을 동작을 알아보자
먼저, 우선순위가 높은 run queue에서 Active list(array)에 있는 task들은 할당된 time slice에 따라 실행된다. 그리고 시간이 지나면 즉, 모든 time silce가 끝나면, Expired list((array)로 이동된다. 그다음 우선순위의 run queue로 이동하여 동작을 반복한다.
이렇게 Active list에 있는 모든 task가 동작하면 이때 list의 전환이 일어난다. list는 포인터에 의해서만 접근할 수 있기 때문에 Active list의 포인터를 Expired list로 바꿔준다. 이때 Expired list는 Active list가 되고 비어있던 Active list는 Expired list가 되는 동작을 한다.

이렇게 전체 프로세스를 스캔하지 않고 다음 실행할 프로세스를 알 수 있기 때문에 프로세스의 수와 상관없이 O(1)의 실행 시간을 가질 수 있다.
하지만, Expired list에서 너무 오래 기다린다면 Actvie queue로 이동할 수 있다.
runqueue에서 real time 프로세서의 우선순위는 0~99번으로 부여했고, 일반 프로세서에 대해선 100~139번의 우선순위를 부여했다. (위 그림에선 반대다)
100~139를 -20~19로 nice value라고 지정했는데, 높은 우선순위(-20)를 받을수록 time silce값을 크게 배정했다.
이렇듯 우선순위(nice value)에 의해 time slice가 정해지니 낮은 우선순위를 가진 프로세스는 빈번하게 context swiching을 하게 된다. nice value에 의해 절대적으로 시간이 나눠지는 unfairness(불공평)이 발생할 수 있다.
이런 문제 때문에 이런 우선순위와 time slice의 mapping을 고려한 현재의 scheduler인 CFS가 나왔다.
CFS Algorithm
- 불공평을 해결하기 위해 CFS는 정한 숫자가 아니라 전체 중에 %로 할당하겠다는 개념을 도입했다. 구체적으론 CPU time의 %로 나눈다는 의미다.
(normal processes scheduler를 CFS, 'SCHED_NORMAL'라고 부른다)
만약 프로세스에 time slice가 10ms가 할당됐는데 1ms에 끝나거나 I/O 이벤트를 만나면 남은 9ms를 반환했다. 또한 10ms를 배정했지만 어떤 프로세스는 하드웨어에 접근하느라 시간이 오래 걸리지만 운영체제는 똑같이 배정했다고 생각했다. 즉, switching cost나 캐시의 접근이나 메모리의 접근, overhead of swap-out/in에 대한 시간 같은 하드웨어적인 요소를 고려하지 않은 것이다. 이렇게 O(1)은 고정적인 time quantum을 배정 하는 것이 문제였다.
이런 시간을 제외하고 실제로 동작한 시간을 기준으로 우선순위를 정하기로 했는데 이 시간을 Virtual runtime ( vruntime )이라고 부른다.
즉, 공평성을 위해 스케줄러는 가장 작은 vruntime을 가진 프로세스를 먼저 실행한다. 다시 말해, 불공평함을 겪은 프로세스들에게 기회와 time quantum을 제공한다.
time slice와는 다르지만 "sysctl_sched_latency"라는 파라미터 ( a.k.a. target_latency )에 통해 CFS가 설정한 스케줄 단위다. 다르게 말하면, target_latency는 프로세스들이 공유하는 전체 CPU time이다.
예를 들어보자,
target_latency가 48ms라 하고, A, B, C, D 프로세스가 있다면, 하나의 프로세스마다 48 / 4 하여 12ms의 time slice가 부여된다. 이때 vruntime이 가장 작은 애를 선택한다. (A를 선택했다고 하자)
계속 동작하다가 C, D가 96ms 이후에 끝났다면, target_latency를 다시 남은 2개의 프로세스로 나눈다. 48 / 2 하여 24ms의 time slice를 조정하여 동작한다.
하지만 만약 target_latency가 20ms인데 프로세스가 40개라면, 각각의 프로세스는 0.5 time slice를 가지고 이에 trash를 발생한다. 이러니 최소한의 시간을 보장해줘야 한다. 그러니 target_latency를 프로세스 중 최소 time slice보다 크게 지정한다. 예를 들어 target_latency = 48ms이고, 10개의 프로세스가 존재하는데 이 중에 가장 작은 time slice가 6이라면 원래는 time slice가 4.8ms이지만 6ms으로 바꿔준다. 정리하면 target_latency의 최솟값에 따라 결정된다.
이렇게 time slice에 대한 해답으로 target_latency를 대안으로 생각했다면 이제 우선순위에 대한 해법을 생각해보자
해답으로 나온 건 가중치다. 가중치를 이용해 time slice를 조절하는 것이다.
40개의 우선순위와 가중치의 관계는 다음과 같이 정의돼 있다. 88761이 가장 높은 가중치와 우선순위를 가진다. 오른쪽으로 갈수록 낮아지고 내려갈수록 낮아진다. time slice를 어떻게 조정하는지 보자.
예를 들어, 2개의 프로세스를 동작하는데 우선순위가 -5에서 A( 3121 )와 0에서 B( 1024 )를 비교해보자.
A의 time slice = ( 3121 / (3121 + 1024)) = 0.753 * sysctl_sched_latency( = assume 48ms ) = 36ms
B의 time slice = ( 1024 / (3121 + 1024)) = 0.247 * sysctl_sched_latency( = assume 48ms ) = 12ms
이와 같이 A는 48ms에서 75%인 36ms로 동작하고 B는 25%인 12ms로 동작한다. time slice의 증가가 가중치에 맞게 변한다. O(1)처럼 고정된 time slice를 가지는 게 아니라 가중치에 따라 증가한다.
vruntime 또한 가중치에 맞게 업데이트돼야 한다. 스케줄러는 vruntime이 가장 작은 애를 먼저 실행한다. 즉, 우선순위가 높은 애를 실행하는데 높은 weight를 가질수록 낮은 vruntime을 가진다. 처음에는 0으로 시작하지만 계속 업데이트되는데 프로세스 중에 가중치가 가장 높은 걸 weight0라고 한다.
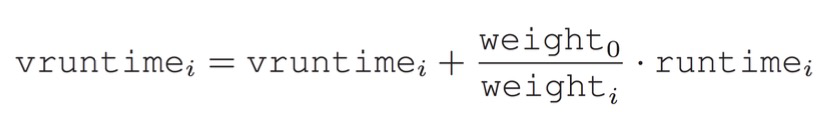
예를 들어보자, target_latency는 20ms이고, 3개의 프로세스를 돌린다고 하면,
| 프로세스 | nice | 가중치 | time slice | cpu burst | vruntime |
| A | 0 | 1024 | (20 * 1024 / 1574) | 7 | 0 |
| B | 5 | 335 | (20 * 335 / 1574) | 3 | 0 |
| C | 7 | 215 | (20* 215 / 1574) | 2 | 0 |
모든 프로세스의 처음 vruntime은 0으로 시작한다.
A_vruntime = 0 +(7 * 1024 / 1024) = 7
B_vruntime = 0 +(3 * 1024 / 335) = 9
C_vruntime = 0 +(2 * 1024 / 215) = 9
이렇게 우선순위가 제일 높은 A가 vruntime이 가장 작다. 그래서 A를 먼저 실행하고 우선순위가 높을수록 vruntime이 천천히 오른다.
그렇다면 어떻게 가장 작은 vruntime을 찾을 수 있을까? 이때 필요한 게 red-black tree라는 것이다.
아래와 같이 vruntime이 작은 애를 가장 왼쪽으로 보낸다.
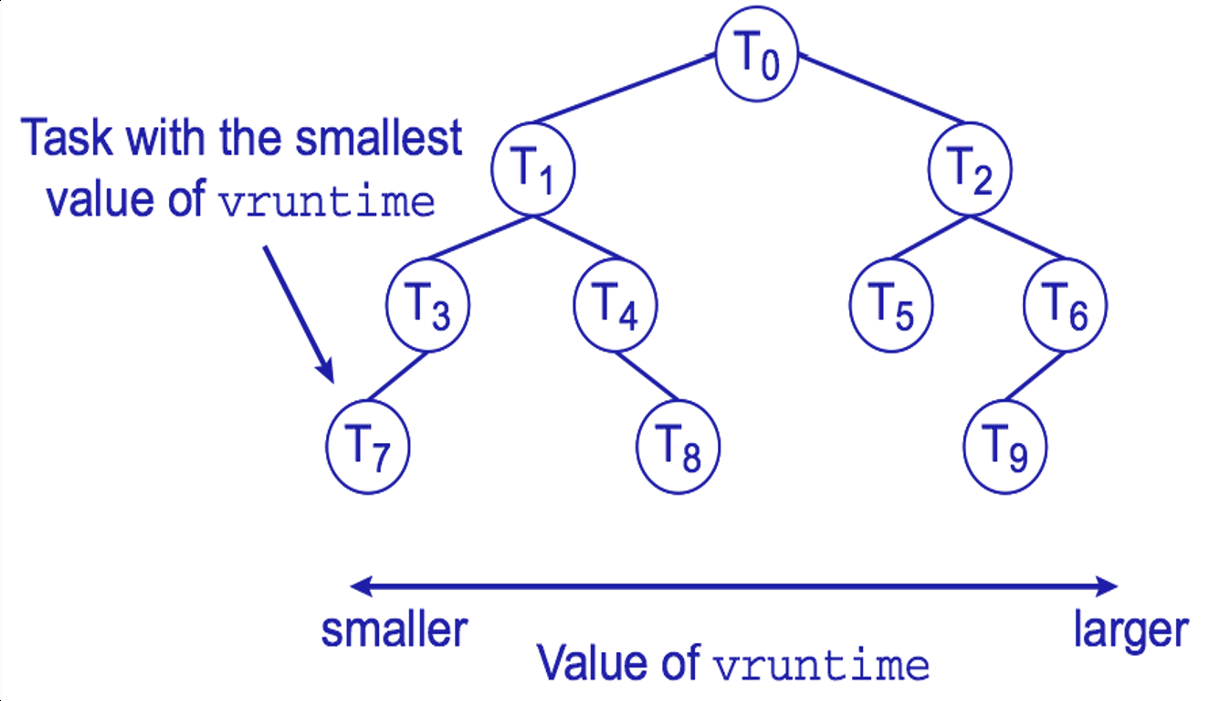
횡설수설 이해하기 어렵다.
그래도 뭔가 느낌은 좀 온다.



댓글