Memory Access instruction
- single-register transfer : 하나의 레지스터를 읽고 쓰는 명령어
- muitiple-register-transfer : 2개 이상의 레지스터를 한 번에 읽고 쓰는 명령어
Single-Register Transfer
1. LDR
- 메모리로부터 주소를 읽어 레지스터에 저장하는 것이다. 단위는 word = 4byte이다.
+ 하나의 byte만 얻고싶을 땐 LDRB나 LDRSB를 사용한다. 근데 레지스터는 word 단위로 돼 있는데 byte만 가져오면 사이즈가 안맞다 이럴 땐 어떻게 해야 할까?
사이즈에 맞게 크기를 맞춰줘야 하는데 LDRB는 zero extensiong하고 LDRSB는 sign extenstion한다.
예를 들면, 아래와 같이 3가지 경우를 볼 수 있는데, 기본 세팅이 아래와 같다고 가정하자
before
r0 = 0x0000_0000
r1 = 0x0009_0000
Mem[0x0009_0000] = 0x01010_1010
Mem[0x0009_0004] = 0x20202_2020
첫 번째, ldr r0, [r1, #4], 간단히 해당 메모리 주소의 값을 저장하는 것이다.
ldr r0, [r1, #4]
after
r0 = Mem[0x0009_0004] = 0x2020_2020
r1 = 0x0009_0000
두 번째, ldr r0, [r1, #4]!로, r1의 주소가 업데이트된다는 점이 !의 차이점이다. 원래는 r1의 값이 변하지 않는데 업데이트 시켜준 것이다. 2개의 명령어로 나눠서 쓰면,
ldr r0, [r1, #4]
add r1, r1, #4
이렇게 나눠서 써야 되는데 아래처럼 하나의 명령어로 쓰면 코드 크기가 줄어든다는 장점이 있다.
ldr r0, [r1, #4]!
after
r0 = Mem[0x0009_0004] = 0x2020_2020
r1 = 0x0009_0004
세 번째, ldr r0, [r1], #4로, []안에 있는 r1의 주소만을 가지고 업데이트하고 #4는 나중에 한다.
2개의 명령어로 나눠서 쓰면,
ldr r0, [r1]
add r1, r1, #4
이렇게 나눠서 써야 되는데 아래처럼 하나의 명령어로 쓰면 코드 크기가 줄어든다는 장점이 있다.
ldr r0, [r1], #4
after
r0 = Mem[0x0009_0000] = 0x0101_0101
r1 = 0x0009_0004
정리하면 [] 안에 있는 주소의 메모리 값을 가져와서 업데이트하는 것이다. 추가적으로 !가 붙어 있다면 Wbit가 1로 세팅된다. write back bit이고 !의 동작은 주소 레지스터까지 업데이트한다는 점이 다르다.

2. STR
- LDR과 반대로 레지스터의 정보를 메모리에 저장하는 것이다. 설명은 위와 같다.
+ 하나의 byte만 얻고싶을 땐 STRB를 하면 된다.
Muitiple-Register-Transfer
위의 single과 다른점은 딱 하나다 그냥 여러개를 가져온다는 차이점이다. LDM과 STM이 있는데 동작은 똑같다.
예를 들어보자

ldm r13! {r0, r1}
stm r13! {r0, r1}
r13에 있는 주소 데이터 값을 {} 안에 있는 레지스터에 저장하고(ldm) 읽어오는(stm) 것이다.
format을 보면 register_list가 있는데 0부터 15까지있으니 총 16개의 레지스터에 저장가능하다. Arm은 16개의 레지스터밖에 없음을 잊지 않았다면, 쉽게 이해할 수 있다.만약 r0, r1, r10에 저장한다고하면, 0,1,10이 1로 세팅된다.
+ stm일 때는 Wbit 오른쪽에 있는 1이 0으로 세팅된다.
+ 모든 레지스터를 적어주기 힘드니 {r0-r12} 이런식으로 "-"를 이용하여 줄이기도 한다.
이외에 IA,IB, DA, DB와 같은 옵션이 있다. 왜 이런 옵션이 있냐면 명확하지 않는 부분을 명확하게 하기 위해서이다. 어떤 부분이 명확하지 않을까?
가령, ldm r12, {r1-r4} 라고 했을 때, r12가 가지고 있는 메모리 주소에서부터 시작하여 r1-r4에 저장하는데 우리는 메모리가 증가하면서 저장한다고 생각하지만, 시작 주소에서부터 내려갈지, 올라갈지가 명확하지 않다. 아무것도 적어주지 않으면 IA가 default로 설정 돼 있다.
IA = increment after, 먼저 메모리를 접근하고 그 다음에 증가한다. (ldmia)
IB = increment before, 먼저 증가하고 메모리에 접근한다. 예를 들면 시작 주소가 r12 + 4 에서부터 시작이다. 즉 시작 주소에 있는 값은 해당하지 않는다. (ldmib)
DA = decrement after
DB = decrement before
이와 같은 STM, LDM동작은 Stack에서도 해당된다. 먼저 Stack을 알아보자
Stack operation
stack이란 뭘까? 스택은 메인 메모리에 존재한다. 다른 말로 back-up register이다. 레지스터에 있는 데이터를 stack에 옮겼다가 (push), 다른 동작이 끝나면 stack에 저장했던 레지스터 데이터를 다시 가져온다(pop). 이와 같은 동작을 Stack operation이라 한다. Arm에선 R13 레지스터가 stack pointer를 담당하는데 메모리에서 스택을 초기화를 해줘야 한다.
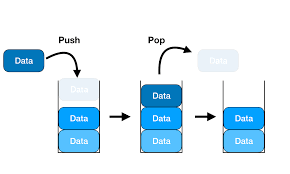
어떻게 보면, 메인 메모링 안에 작은 메모리라고 볼 수 있다. 그러니 메모리에 접근하는 LDM, STM의 동작을 똑같이 하는 것이다. 그렇다면 똑같이 위에서 배운 LDM, STM을 쓰면 될까??
Arm에서는 똑같은 동작을 하지만 사용자의 편리성을 제공해주기 위해 Stack에서의 STM, LDM을 따로 만들었다. 동작은 똑같지만 이름만 달리 만든 것이다. 즉, pseudo 명령어를 만들었다. 아래 표를 보면 알 수 있다.
(default = STMFD, LDMFD)

'시스템 반도체 > Arm' 카테고리의 다른 글
| Arm SWAP Instruction ( 메모리 접근, SWP, MESI protocol, LDREX, STREX ) (0) | 2022.04.07 |
|---|---|
| Arm Memory Map ( 메모리 맵, 메모리 공간 분할, I/O ) (0) | 2022.04.07 |
| Arm Branch instruction ( 분기 명령어, B, BL ) (0) | 2022.04.07 |
| Arm Aruthmetic instruction ( 산술 명령어, ADD, ADC, SUB, SBC, RSB, RSC, CLZ ) (0) | 2022.04.07 |
| Arm Move instruction ( 이동 명령어, MOV, MVN, MOVS ) (0) | 2022.04.07 |




댓글