CPU Scheduling Algorithms
Scheduling 알고리즘을 4가지 정도 알아보자. 이때 성능 평가 지표는 평균 waiting time으로 보겠다.
CPU Scheduling에 대해서 잘 모르겠다면 앞선 글을 참고하면 좋다.
운영체제 CPU Scheduling ( CPU 성능 평가 지표, Preemptive, Dispatcher, non-Preemptive, cpu burst )
CPU Scheduling - cpu는 운영체제에 의해 계속 동작을 수행한다. 이렇게 계속 동작하게 하기 위해 scheduling을 통해 cpu가 멈추지 않고 동작하게 하는 것이다. 이런 동작의 단위를 burst라고 한다. 컴퓨터
wpaud16.tistory.com
1. FCFS ( First-come, First Severd )
- 동작한 순서대로 처리하겠다는 의미다. Non-preemptive 방법이라 볼 수 있다. 백그라운드 프로그램에서 자주 사용하는 알고리즘이다.
예를 들어보자


p1, p2, p3순서대로 왔으니, p1의 시간이 길더라도 먼저 처리하는 것이다.
waiting time은 (마지막 시작 시간 - 도착 시간 - 프로세서에 대한 cpu 동작 시간)으로 계산된다.
도착시간은 없으니 0이고 프로세서 동작 시간도 0이니 프로세서의 시작 시간이 곧 waiting time이다.
p1 = 0, p2 = 24, p3 =27이 된다. 이에 평균 대기 시간은 17이 된다.
만약 p2, p3, p1의 순서대로 도착했다면 어떻게 될까? 평균 대기 시간은 17이 아니라 3으로 확 줄어든다.

이렇게 하나의 동작 때문에 수행 시간이 확 늦어지는 효과를 Convoy effect라고 부른다.
2. SJF ( short Job First )
- 다음 cpu burst에서 가장 짧은 애를 다음에 할당하는 알고리즘이다. 도착 순서와는 상관없다. 아마 가장 작은 평균 대기 시간을 제공하는 알고리즘이다.
예를 들어보자


도착 순서대로 번호를 할당했지만, 가장 짧은 p4가 먼저 실행되고 그다음으로 짧은 p1이 실행되는 방식이다. 평균 대기 시간은 7로 FCFS보다 약 10ms가 더 빠르다. SJF는 Non-preemptive 방법과 preemptive 방식으로 구현할 수 있다.
Non-preemptive방법은 수행 중에 더 짧은 애가 도착하더라도 이미 수행 중이므로 다 끝날 때까지 기다려야 한다.
예를 들어보자, 아래와 같이 도착 시간과 burst 시간을 보면 제일 짧은 p3이 먼저 실행돼야 하지만, 먼저 도착한 p1이 실행되고 그 뒤에 p2가 왔다고 해도 이미 실행 중이라 p1이 끝날 때까지 기다린다.
평균 대기 시간은 어떻게 될까? 여기엔 도착시간이 나와 있기 때문에 도착 시간을 고려하여 정한다.
(마지막 시작 시간 - 도착 시간 - 프로세서에 대한 cpu 동작 시간)
P1 = 0 - 0 - 0 = 0
P2 = 8 - 2 - 0 = 6
P3 = 7 - 4 - 0 = 3
P4 = 12 -5 - 0 = 7
따라서 평균 대기 시간은 4이다.

preemptive 방법은 이미 수행 중이더라도 더 짧은 애가 도착하면 scheduling을 통해 짧은 프로세서를 실행한다. ( shortest remaining time first )
예를 들어보자 위와 동일한 상황이라면 어떻게 될까?
P1이 먼저 도착하여 실행했지만 2ms가 지난 뒤에 P2가 도착했는데 P1보다 짧기에 P2를 실행한다. 또 P3가 도착했는데 P4보다 더 짧기 때문에 P3를 동작한다.
평균 대기 시간은 얼마일까?
P1 = 11 - 0 - 2 = 9
P2 = 5 - 2 - 2 = 1
P3 = 4 - 4 - 0 = 0
P4 = 7 - 5 - 0 = 2
따라서 평균 대기 시간은 3으로 Non-preemptive보다 1ms 더 짧다.
그런데 보다 보니 이런 궁금증이 생긴다. 만약 P3가 2ms라고 하면 P3가 도착했을 때 P2도 2ms 남았는데 어떻게 할까?
만약 동일하다면 기존의 프로세서를 계속 실행한다. 즉 P2가 다 끝나고 P3를 실행한다.

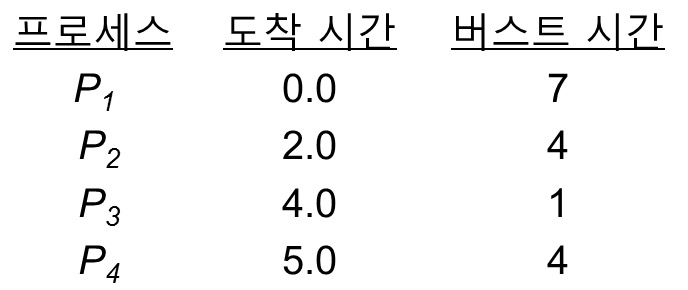
3. Round Robin (RR)
- 각각의 프로세스에게 time quemtum을 주는 방식이다. 무슨 소리냐 하면 일정 시간 동안만 프로세서를 처리하고 시간이 지나면 다른 프로세서를 처리한다는 말이다.
또 다르게 말하면 위에서 봤던 burst 시간, 우선순위 상관없이 모두 공평하게 정한 q 시간 동안 동작한다는 의미다.
수식적으로는 n개의 프로세스가 ready queue에 들어가 있고 time quantum이 q라면, 각각의 프로세서는 (n-1)*q 시간보다 더 기다릴 필요는 없다는 의미다.
만약 q가 굉장히 크다면 FCFS와 유사한 알고리즘이 된다. FCFS란 먼저 들어온 애를 먼저 처리하는 것인데 굉장히 크니, 어차피 q가 끝나기 전에 프로세스가 끝난다는 의미다.
반대로 q가 굉장히 작다면 context switch가 너무 많이 발생한다. time interrupts가 발생하니 프로세서보다 운영체제 자체 code가 더 많이 수행된다.
예를 들어보자, q가 4라고 했을 때 동작하는 방식이다.


보니 q보다 P2, P3의 시간이 더 짧다. 이때는 2가지 옵션이 있다. 그냥 idle 상태로 내버려 두거나 OS코드를 수행하는 방법이 있다. 이것 또한 design choice이다. 어떤 특징이 있나 보면 대게 Turnaround time이 SJF보다 길다.
왜냐면 Turnaround는 프로세서가 동작을 시작해서 끝나는 시간을 의미하는데. 여러 번 수행되는 RR과 반대로 SJF는 한번 실행되면 계속 수행한다. 또한 시작은 일찍 하지만 끝나는 건 burst 시간보다 오래 걸리고 무엇보다 context-switch-time이 누적된다. 이런 이유 때문에 RR이 Turnaround 시간이 더 크다.
그렇다면 q의 시간이 늘어날수록 Turnaround time은 줄어들 것 같지만 실제로는 또 그렇지 않다. 응답 시간은 더 짧다.
q에 따른 비교는 아래와 같다.
4. Priority Scheduling
- RR을 쓰면 중요하지 않은 프로세서도 수행해야 하기 때문에 중요한 프로세스가 비교적 늦게 끝나는 상황이 온다. 이런 점을 보완하기 위해 우선순위를 메겨 처리하는 방법을 Priority Scheduling이라 한다.
말 그대로 프로세서에 우선순위 번호를 할당하고 그 순위에 맞게 처리한다. 이때 높은 숫자부터 처리할지 낮은 숫자부터 처리할지는 선택사항이다. 여기선 0이 가장 높은 우선순위를 가진다고 가정하겠다.
이번에도 역시 Non-preemptive와 preemptive가 존재한다.
Non-preemptive를 보면 burst time이 아닌 우선순위를 기준으로 동작하는 걸 볼 수 있다.


문제점은 낮은 우선순위를 가진 프로세서는 영원히 실행되지 않을 수도 있다는 점이다(Starvation). 이런 점을 해결하고자 Aging이라는 방법을 이용하여 해결했다. Aging이란 일정 시간이 지나면 우선순위를 증가하거나 감소하는 방법이다.
Burst time
- 하지만 우린 위에서 봤던 것처럼 실제 CPU의 burst time을 모른다. 그렇기에 다음 CPU burst를 실제값과 비슷한 값을 예측해야 한다. 식은 아래와 같다.
tn (시간) = 현재 실행된 실제 CPU burst 시간이다
𝜏n (타우) = 이전에 예측한 CPU burst 시간이다. 저장되는 값이다.
𝛼는 0 이상 1 이하의 값을 가지고 이 값을 조정하면서 현재와 이전 값의 관계를 조절한다.
즉 𝜏n는 예측 값이고 t는 실제 값이다.

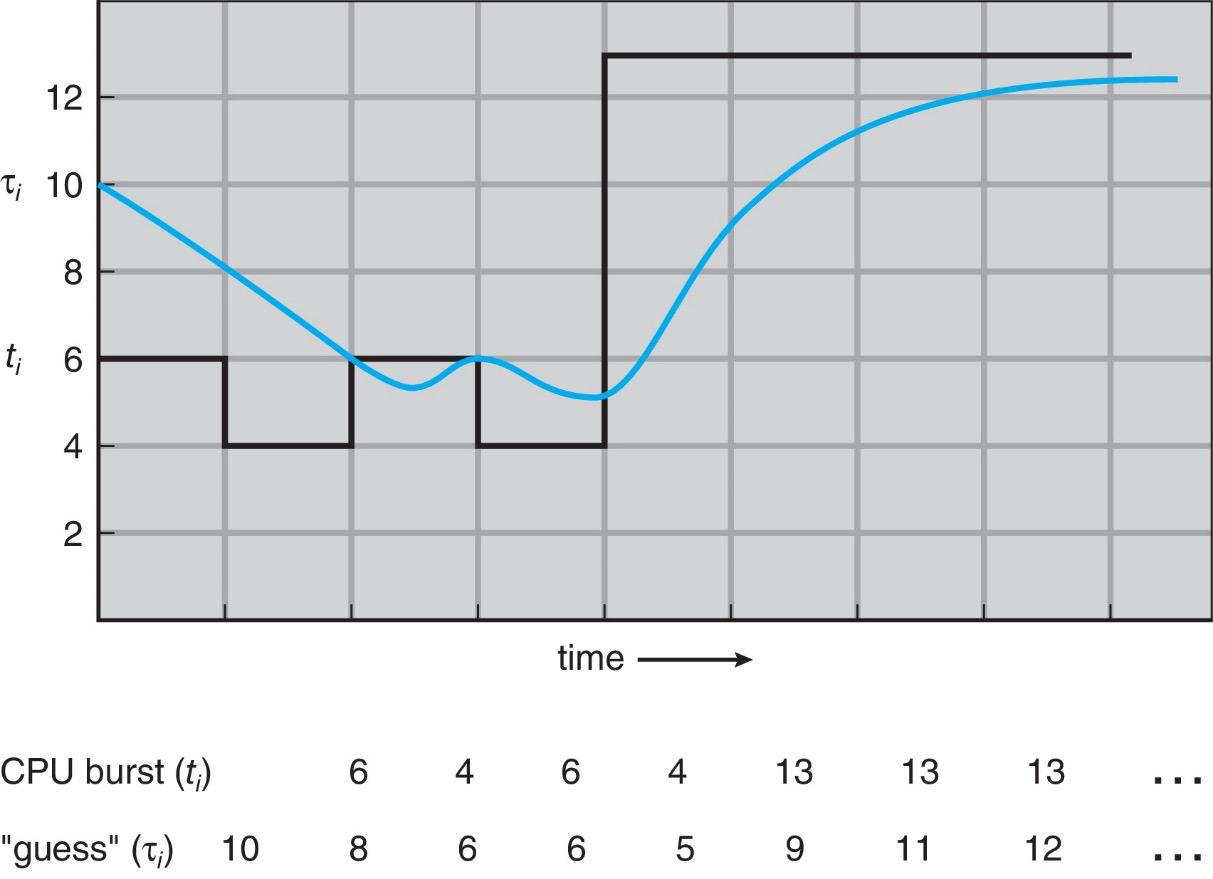
예를 들어보자, 𝜏n = 10, 𝛼 = 0.5라고 했을 때, 실제 시간과 예측하여 나온 시간을 표로 그린 값이다.
검은색이 실제 값이고 파란색이 예측값이다.
똑같진 않지만 유사한 추세로 움직이는 걸 알 수 있다.
𝜏1을 보면 0.5 * 6 + [ (1 - 0.5)*10 ] = 8로 나온다.



댓글