Clustering(클러스트링)이란, 번역하면 군집, 집단, 무리라는 뜻을 가진다. 데이터의 관점에선 주어진 데이터들의 특성을 고려해 집단을 정의하고 집단의 대표할 수 있는 대표점을 찾는 것으로 데이터 마이닝의 한 방법이다.
클러스트링에는 여러 방법이 존재한다.
1. 평균 기반
2. 계층 기반
3. 밀도 기반
4. 연결 기반
이중에 이번에는 Spectral Clustering을 알아볼까한다. 많은 경우에서 기존의 클러스트링 알고리즘보다 더 나은 성능을 보인다.

Spectral Clustering는 거리가 가까이 있더라도 연결이 없다면 군집화하지 않는다.
크게 3가지 절차를 거쳐 클러스트링을 진행한다.
첫 번째로, 각각의 데이터 포인트를 유사도에 따라 행렬(그래프)로 변환시킨다.
- 좀 더 쉽게 생각하면, 신호를 주파수 도메인으로 변경하면 쉽게 풀리는 것과 같은 이유다. 1번을 기준으로 나머지 번호들과 유사도를 기준으로 행렬을 만든다.
이때, 어떤 유사도를 쓰는지는 약 3가지 정도가 있다. 간단히 보면
1. Epsilon-neighbourhood Graph : Epsilon을 고정시켜 그 반경에 있는 애들과 다 연결한다, 가중치와 방향성은 없다
2. K-Nearest Neighbours : k점을 고정시켜 2개의 벡터를 이동하며 연결한다. 가중치와 방향성이 있다.
3. Fully-Connected Graph : 모든 점들이 다 연결돼 있다. 거리를 기준으로 나뉜다. 거리의 계산은 보통 가우시안 유사도를 따른다

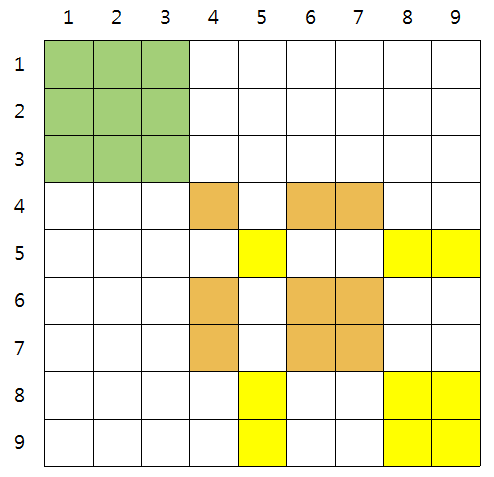
두 번째로, 유사도 행렬에서 주성분을 뽑아내다. (PCA)
- 위 그림 오른쪽 행렬에서 주요한 성분을 뽑아낸다. 위에서 주성분은 열을 기준으로 초록색과 주황색, 노란색을 띤 열이 주성분이 될 것이다. (고유벡터, 고유값 기준) (1열, 4열, 5열 == 3차원)
그리고 각 점을 주성분을 기준으로 행렬 비교하며 변환한다. 그러면 주성분이 3개니 3차원으로 나타날 것인데, 하나하나의 주성분과 비슷한 요소(데이터)끼리 모인다.

세 번째로, 변환된 그래프에서 클러스트링을 진행한다.
- 주로 KMeans를 사용한다. KMenas를 연결성에 중점을 둔 알고리즘이라고 할 수 있다.
파라미터는 아래와 같다.


어렵다 어려워~~
'개발 Tools > 파이썬_Deep learning & ML' 카테고리의 다른 글
| 딥러닝을 위한 기초 개념 Entropy ( Cross entropy, KL divergence, 엔트로피 ) (0) | 2022.05.02 |
|---|---|
| 머신러닝 KMeans Find Optimal k ( Elbow Method, Silhouette Method ) (0) | 2022.03.24 |
| 머신러닝 fit_transform() 과 transform()의 차이점 (0) | 2021.12.12 |
| 딥러닝 LSTM (Long Short-Term Memory) (0) | 2021.10.22 |
| 딥러닝 신경망 기본 (신경망, 랭크, 다층 퍼셉트론, 활성화 함수, 역전파) (0) | 2021.10.16 |



댓글