성능을 평가하는데 여러 지표를 사용합니다. 하나만 가지고 평가할 순 없기 때문입니다.
각각의 지표별 특징을 얘기하려 합니다.
혼돈 매트릭스 (confusion matrix)
혼돈 매트릭스 또는 오차 행렬이라고도 합니다 이건 성능 지표는 아니고 지표들이 이 혼돈 매트릭스의 조합으로 이루어집니다.
혼돈 매트릭스의 표는 이렇습니다.
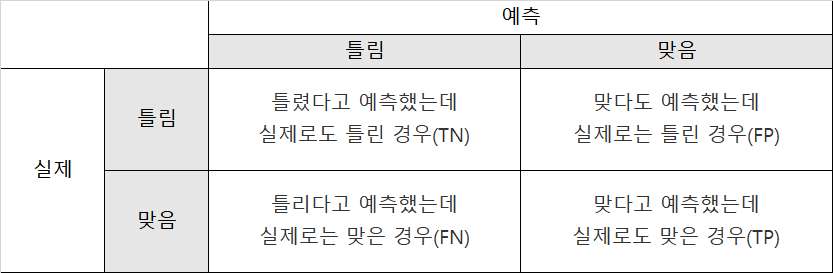
T = True
F = False
N = negative
P = positive
이렇게 표로 주어집니다. 표를 보고 여주는 코드도 있습니다.
from sklearn.metrics import confusion_matrix, classification_report
confusion_matrix(정답, 예측)
classification_report(y_test, y_predict)
정답에는 실제 정답을 주고, 예측에는 우리가 predict으로 예측한 값을 주면 됩니다.
표를 보여주는 코드는 "classification_report"입니다.
정확도 (accurcy)
정확도는 말 그대로 얼마나 많이 맞췄냐를 보는 겁니다. 확률로 보면, 전체의 경우 중에 맞은 경우에 대한 확률이겠죠?
수식으로는 (TN+TP) / (전체)입니다.
간단하지만 허점이 많습니다. 예를 들어보겠습니다. 만약, 100명 중에 10명이 환자라고 한다면 우린 다 정상이라고 해도 90%의 정확도를 가집니다. 이건 중요한 선택이기에 90%는 높은 숫자이지만 의미가 없는 숫자입니다.
이처럼 불균형한 데이터에선 적합하지 않습니다.
from sklearn.metrics import accuracy_score
accuracy_score(정답, 예측)
정밀도 (precision)
정밀도는 맞다고 예측한 애들 중에 실제로 맞은 애들의 비율입니다.
수식으로는 TP / (FP+TP)입니다
높은 정밀도를 얻기 위해선 FP를 낮추는데 힘을 써야 합니다.
from sklearn.metrics import precision_score
precision_score(정답, 예측)
재현율 (recall)
재현율은 실제로 맞은 사람들 중에 맞았다고 예측한 애들의 비율입니다.
수식으로는 TP / (FN+TP)입니다
높은 재현율을 얻기 위해선 FN을 낮추는데 힘을 써야 합니다.
from sklearn.metrics import recall_score
recall_score(정답, 예측)
F1 스코어
정밀도와 재현율은 서로 트레이드오프 관계에 있습니다. 하나가 올라가면 하나는 떨어집니다. 하나는 높은데 다른 하나는 낮은 점수라면, 좋은 결과는 아닙니다. 둘 다 높은 점수를 맞아야 좋은 모델이라 할 수 있습니다.
그렇다면 어떻게 해야 할까요? 그래서 나온 지표가 F1스코어입니다. F1 스코어는 정밀도와 재현율의 조화 평균을 따릅니다.
수식은 2 / [(1/recall) + (1/precision)]입니다.
각각의 값이 조화롭게 높이 나왔을 때, 최고점을 갖습니다. 제가 생각했을 땐 F1 스코어로 평가하는 게 제일 좋은 방법 같습니다.
from sklearn.metrics import f1_score
f1_score(정답, 예측)
ROC, AUC
ROC는 그래프입니다.
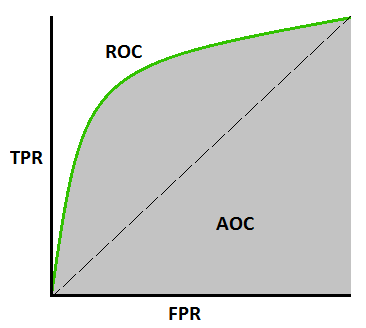
맞출 때마다 TPR(수직) 방향으로 한 칸씩 올라갑니다. 그리고 틀리면 FPR(수평) 방향으로 이동합니다. 그래서 직사각형 모양일수록 확률이 좋은 것입니다.
하지만 ROC는 그래프 자체입니다. 따라서 지표로 사용하기엔 적합하지 않습니다. 지표로 사용하는 건 AOC입니다.
AOC란, 넓이를 말합니다. 우린 이 넓이가 1에 가까울수록 좋은 모델임을 알 수 있습니다. 왜냐면 많이 맞출수록 위로 그래프는 위로 올라가는 모양을 띄우기 때문입니다.
from sklearn.metrics import roc_auc_score
roc_auc_score(정답, 예측)
'개발 Tools > 파이썬_Deep learning & ML' 카테고리의 다른 글
| 머신러닝 앙상블 보팅(Voting) (0) | 2021.08.06 |
|---|---|
| 머신러닝 결정트리 (지니계수, 정보 이득 지수, min_samples_split, min_samples_leaf, max_features, max_depth, max_leaf_nodes, graphviz) (0) | 2021.08.02 |
| 머신러닝 preprocessing(데이터 전처리) ( classes_, LabelEncoder, get_dummies) (0) | 2021.07.20 |
| 머신러닝 MinMaxScaler(정규화) (0) | 2021.07.15 |
| 머신러닝 StandardScaler(표준화) (0) | 2021.07.15 |


댓글