CNN ( Convolution Neural Networks )은 입력이 이미지라는 전제로부터 시작한다.
CNN은 DNN의 문제로부터 나왔다. DNN은 입력을 1차원으로 flatten 시켜서 입력으로 주어지는데 이때 이미지가 가지고 있던 여러 정보들이 손실된다. 또한 학습 시간이 길기도 하다.
그렇다면 CNN은 어떻게 동작할까??
실제로 우리 인간은 어떤 걸 볼 때, 특징을 뽑아내서 어떤 물체인지 판단한다고 한다. 이런 개념과 동일하게 이미지를 보고 판단한다. 아래 그림에서 강아지를 분류할 때 꼬리와 발과 머리를 보고 판단하는 것처럼 부분 부분을 뽑아서 본다.
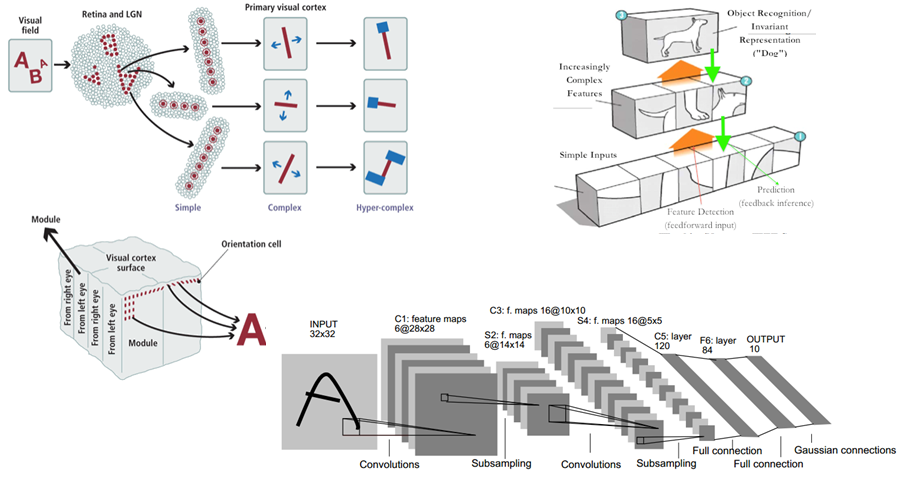
또한 CNN은 이미지의 특징을 추출하는 부분과 클래스를 분류하는 부분으로 나눌 수 있다.
추출하는 부분은 convolution층과 활성 함수 층과 pooling 층으로 구성되고 클래스를 분류하는 부분은 ANN(DNN)처럼 Fully connected 된 층으로 구성된다.
하나하나 층에 대해 알아보자
Convolution
간단히 말하면 곱해가면 더하는 것이다. 아래에서 노란색에 해당하는 것이 Filter에 해당한다.
filter와 image를 곱해서 map을 만든다.
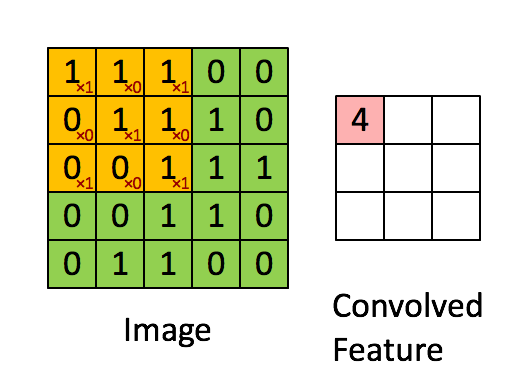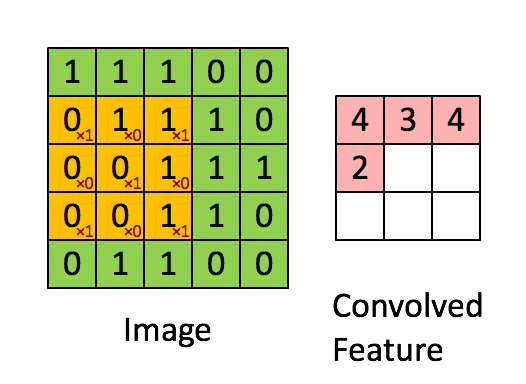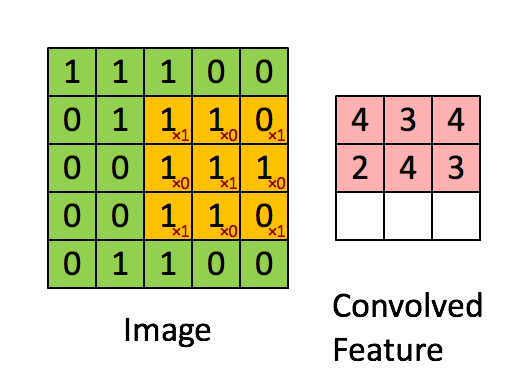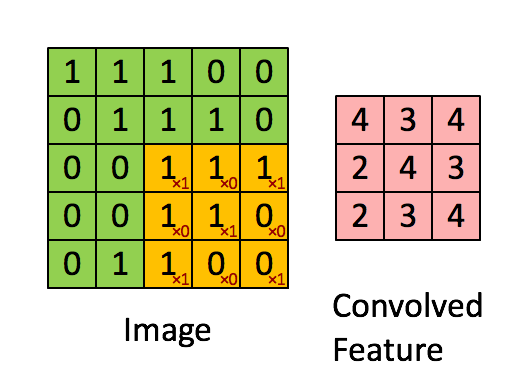
간단한 예를 통해 보자.
아래와 같은 filter에서 흰색은 0이고 검을수록 숫자가 높아진다고 하자. 그렇다면 검은색 선은 왼쪽과 같이 나타낼 수 있다.


저런 필터를 가지고 쥐 이미지를 전체적으로 탐색한다 했을 때. 엉덩이 부분이 필터의 모양과 유사함으로 합성곱을 하면 큰 값이 나올 것이다. 그리고 활성 함수를 통과시키면 조금 더 정제된 값으로 나타날 것이다.
우리는 필터의 W를 업데이트시키는 것이 목표다. 정리하면 이미지에 맞는 특징에 잘 반응하게 하는 filter를 찾기 위해 W를 조절하는 것이다.
Channel
channel은 쉽게 말해 색의 표현이다. 3 channel이라면 RGB를 의미한다.
대부분의 이미지를 우린 RGB로 표시할 수 있는데 각각의 R channel과 G channel과 B channel이 자신만의 Filter를 가져서 모든 합성 곱을 한 후에 더하면 Feature Map이 되는 것이다.
아래 예를 들어보면 각각의 필터끼리 곱하여 더한 값이 하나의 Map이 된다.


이때 가장 중요한 것은 입력의 channel과 Filter의 channel이 같아야 하는 점이다.
Strid
Strid는 간단히 말해 얼마나 띄엄띄엄 합성곱을 할 것인가를 의미한다.
아래 그림으로 바로 느낌 올 것이다.

Output size
위에 strid 그림을 보면 같은 Filter를 사용하는데 출력 사이즈가 달라지는 것을 볼 수 있다.
strid 수와 filter의 크기에 따라 출력 사이즈가 어떻게 바뀌는지 보자

- input size: m × m
- filter size: k × k
- stride: s라고 가정한다면

예를 들어보자 m = 7, k = 3라고 한다면 s를 바꿔가며 계산했을 때 결괏값이다.
s = 1 ⇒ (7 − 3)/1 + 1 = 5
s = 2 ⇒ (7 − 3)/2 + 1 = 3
s = 3 ⇒ (7 − 3)/3 + 1 = 2.3 (not fit)
s가 3일 때는 소수가 나와서 맞지 않는다. strid의 수가 크면 정보 손실이 조금 있겠지만 연산량을 줄어든다.
Padding
그런데 계속 합성곱을 하며 연산을 반복해 가면, 출력 사이즈가 줄어드는 것을 알 수 있다.

이유는 당연하다. 우린 합성곱을 할 때 필터와 입력의 크기에 맞게 곱해줘야 하니까 가운데를 맞춰서 합성곱을 한다. 이렇게 하다 보면 모서리 부분의 값들이 중앙에 맞춰서 합성곱을 하지 못한다. 합성곱을 하지 못하면 모서리 부분의 정보를 잃어버리는 것이다. 즉, 정보의 소실이 생기며 크기가 줄어든다.
이를 방지하고자 padding이라는 개념이 들어왔다. 우리가 입는 패딩처럼 몸집을 키우는 것이다. 어떤 패딩을 입느냐는 선택이다. 그중에서 가장 대표적인 padding이 zero padding이다. 0으로 다 채워서 넣는 것이다. 아래 그림을 보면 이해가 될 것이다.

이렇게 되면 위에서 봤던 output size도 달라진다. padding의 크기가 고려돼야 한다. 양끝에 들어가니까 2P를 더 해준다.
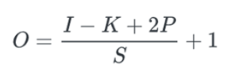
I = 입력 사이즈
K = 필터 사이즈
P = 패딩 크기
S = strid 크기
Pooling
Pooling이란 간단히 말하면 뽑아오는 것이다. 연산량을 줄일 수 있고 필요한 값을 두드러지게 볼 수 있다.
간단히 말해서 새로운 filter를 하나 추가하는 효과다. 2x2 필터를 pooling으로 지정하면 25%만 뽑아서 쓰겠다는 의미다.
output size의 계산은 다음과 같다.

P는 pooling의 size이고 S는 Strid의 size다.
아래는 pooling을 하는 방식의 예시가 2개 있다. 하나는 필터 내에서 가장 큰 값을 뽑아오는 Max Pooling이고 다른 하나는 필터의 평균을 취하는 Average Pooling방법이 있다.

위에서 봤던 strid나 pooling은 둘 다 크기를 줄이는 방법인데 둘 다 사용하는 것보단 요즘에는 strid를 주로 사용한다.
간단한 코드
from keras.datasets import mnist
from keras.utils import to_categorical
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32')/255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32')/255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3,3), activation='relu', input_shape = (28, 28, 1)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(10, activation='softmax'))
model.summary()
model.compile(optimizer= 'rmsprop',
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
model.fit(train_images, train_labels, epochs=3, batch_size=64)
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('test_loss = ',test_loss)
print('test_acc = ',test_acc)
정리
CNN은 이미지를 보다 더 잘 분류하기 위해서 나온 개념이다.
이미지를 여러 필터를 거쳐서 입력 이미지를 잘 분류하기 위해 필터의 W를 조절하는 것이다. 그 과정은 합성곱을 거치고 활성 함수를 거친 후에 선택적으로 사이즈를 줄이기 위해 pooling을 거친다. 이 과정에서 strid와 padding을 지정해준다.
지정한 layer만큼 반복하다가 FC layer에 들어가기 전에 flatten 하여 FC층을 거쳐서 이미지가 어떤 클래스에 속하는지 분류한다.
'개발 Tools > 파이썬_Deep learning & ML' 카테고리의 다른 글
| 딥러닝 RNN의 모든 것이었으면 좋겠다 ( Bidirectional RNN, Deep RNN, Seq2seq, Attention Mechanism ) (0) | 2022.06.09 |
|---|---|
| 딥러닝 DNN, ANN의 모든 것이었으면 좋겠다 ( back propagation, error ) (0) | 2022.05.19 |
| 딥러닝 Softmax function (소프트 맥스) (0) | 2022.05.19 |
| 딥러닝을 위한 기초 개념 Gradient decent (2) | 2022.05.12 |
| 딥러닝을 위한 기초 개념 Perceptron ( 활성함수, DNN ) (0) | 2022.05.04 |




댓글